以前一直没有搞明白SSRS里面的RowNumber函数到底该怎么用,所以一直没有很好的办法在SSRS中的表格上实现隔行变色的样式,实现隔行变色的关键就是获取表格中每一行的行号。在最近了解了下这个函数,发现RowNumber函数“在某些时候”获取行号还是非常有用的,之所以说“某些时候”是因为RowNumber函数获取的行号实际上是数据集中最小粒度行的行号,这是什么意思呢?意思就是RowNumber函数只能用来计算数据集的行号,如果报表上Tablix(Matrix,Table等控件都是基于Tablix)中分组的粒度比数据集行要大那么RowNumber函数就无能为力了,因为RowNumber永远都是基于数据集中的行来计算行号的,所以其计算出来行号的粒度永远都是和数据集的粒度保持一致。
那么我们现在来看看RowNumber函数的概念,RowNumber函数使用的时候要传一个参数,参数就是数据范围(Scope)的名称,SSRS中数据范围(Scope)一般指的就是行组、列组、数据集等可以划分数据范围的数据结构,RowNumber函数在运行的时候会根据当前所在的数据范围迭代过的记录来计算数据集中的行计数,从而生成行号,而RowNumber函数参数是用来指定重置行计数的数据范围的。前面这句话说的很抽象不好理解,下面我们通过图文结合方式来详细介绍下RowNumber函数的使用以方便理解。
假设我们现在的报表上有一个数据集叫DBSet用来获取数据库中的数据

然后我们在报表上定义了一个Matrix用来展示数据集DBSet中的数据,我们只用到了Matrix的一个行组(行组名DateID),该行组通过数据集DBSet字段DateID来分组,而字段DateID的粒度也是数据集DBSet的最小粒度,也就是说在数据集DBSet中字段DateID每一行的值都是不同的。

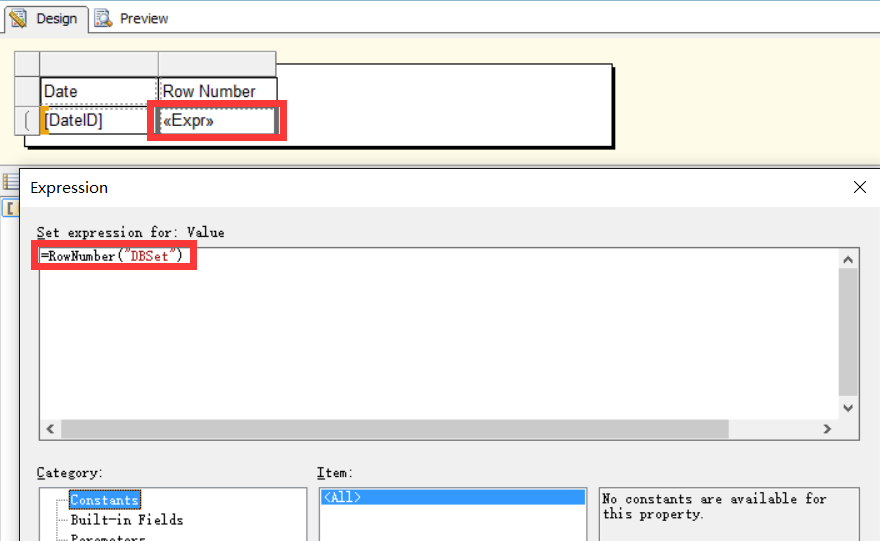
然后我们在Matrix上定义了一列Row Number用于显示当前行的行号,行号通过我们本文中所述的RowNumber函数来生成,RowNumber函数的参数是设置的数据集DBSet的名称,所以RowNumber函数的行计数范围是整个数据集,行计数在Matrix上永远都不会被重置。
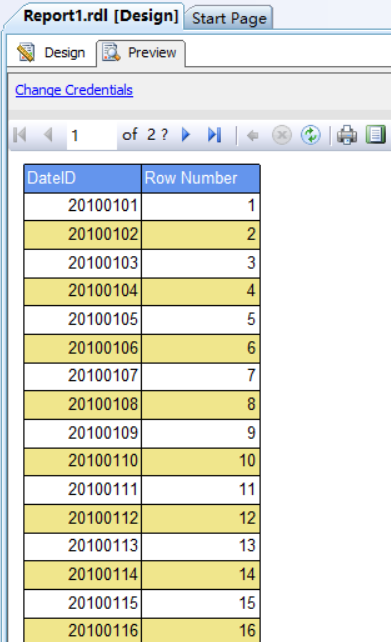
而上图中RowNumber函数是位于行组DateID中的单元格内的,所以RowNumber函数当前所在的数据范围就是行组DateID,所以RowNumber函数会根据行组DateID的迭代范围来做数据集的行计数,我们来看看运行报表的结果:

在上图中我们看到,当列Date为20100101时,Matrix中行组DateID只迭代过数据集中一行数据,所以这时RowNumber函数返回的结果是1。当Date为20100102时,Matrix中行组DateID迭代过的DateID值为20100101、20100102,所以行组DateID的当前迭代包含数据集中的两行数据,所以RowNumber函数返回的结果是2。而当Date为20100103时,Matrix中行组DateID迭代过的DateID值为20100101、20100102、20100103,所以行组DateID的当前迭代包含数据集中的三行数据,所以RowNumber函数返回的结果是3。以此类推所以RowNumber函数在行组DateID上每一行的迭代就生成了整个Matrix的行号。
在上面这个例子中我们了解到了RowNumber函数可以用来生成行号,但是RowNumber函数的参数可以用来做什么并没有很好地被体现出来。我们将上面的例子稍作修改如下,我们在行组DateID上添加了一个父组叫YearMonth,根据数据集中的字段YearMonth来进行分组,字段YearMonth的粒度要比DateID大,所以在数据集DBSet中字段YearMonth和字段DateID是一对多关系,也就是说一个YearMonth值包含多行DateID记录。
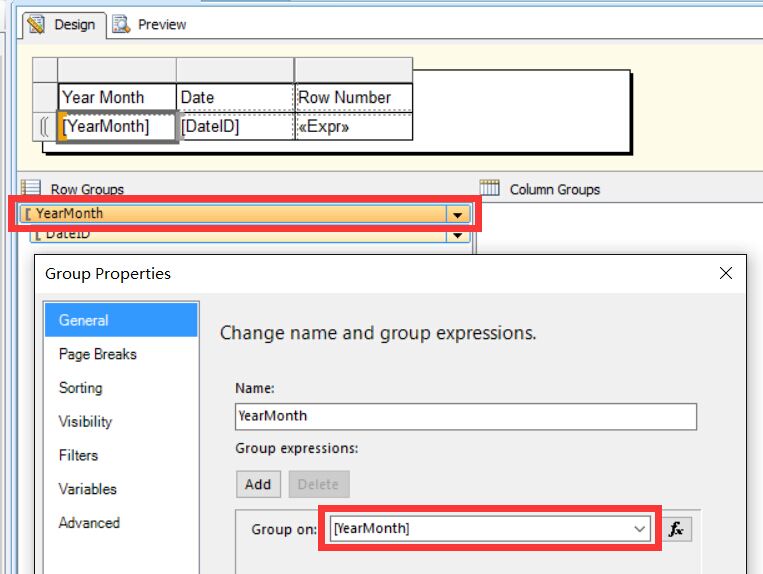
紧接着我们将列Row Number的表达式改为了RowNumber("YearMonth"),我们将RowNumber函数的参数指定为了Matrix的行组YearMonth,那么根据我们上面所述,现在RowNumber函数会根据行组YearMonth的迭代值来进行行计数重置,当行组YearMonth的迭代值发生变化的时候RowNumber函数的行计数会清0。
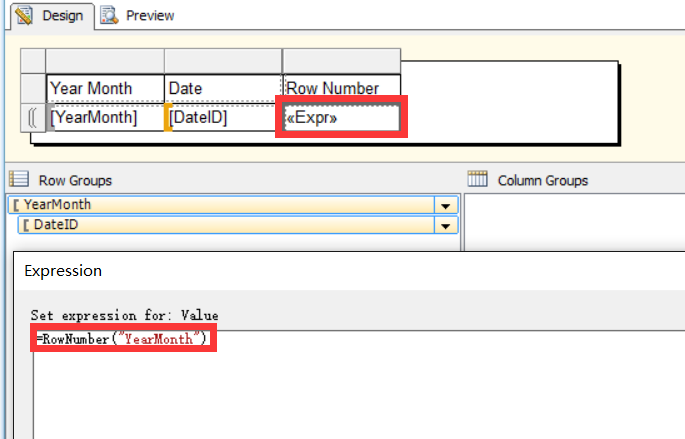
根据上图的修改,我们再次运行报表结果如下,我们可以看到RowNumber函数返回的行计数在行组YearMonth的值变化后又从1开始了,印证了我们上面所说的当RowNumber函数参数指定的数据范围的迭代值发生变化后RowNumber函数的行统计被清0了。

在本文开始的时候我们说了RowNumber函数是在“在某些时候”可以用来获取行号,上面的例子中Matrix的最小粒度也就是行组DateID的粒度,而DateID的粒度和数据集DBSet的粒度刚好一致,所以用RowNumber函数来返回行号是没有问题的,也就是我们本文中提到的“在某些时候”。但是如果Matrix的最小粒度要比数据集DBSet的粒度要大,那么用RowNumber函数来返回行号就是不行的了,现在我们将上面的例子再稍作修改如下:

我们删除了行组DateID只留下了行组YearMonth,那么现在Matrix的最小粒度就是行组YearMonth了,然后我们将列Row Number的表达式改回RowNumber("DBSet"),那么RowNumber函数的行计数重置范围又变回整个数据集了,行计数在整个Matrix上不会被清0。运行报表我们查看到结果如下:

可以看到每一行的行计数都不正确了,为什么会出现这样的结果呢?我们来分析下,RowNumber函数当前所在的数据范围就是行组YearMonth,所以RowNumber函数会根据行组YearMonth的迭代范围来做数据集的行计数。当行组YearMonth等于201001的时候,行组YearMonth迭代了数据集中31行数据,所以RowNumber函数返回值31。当行组YearMonth等于201002的时候,行组YearMonth迭代了数据集中YearMonth为201001、201002的数据集行总共59行数据,所以RowNumber函数返回值59。当行组YearMonth等于201003的时候,行组YearMonth迭代了数据集中YearMonth为201001、201002、201003的数据集行总共90行数据,所以RowNumber函数返回值90。以此类推行组YearMonth的每一次迭代都会把从201001到当前行包含的数据集行数作为RowNumber函数的返回值,所以就有了上图中报表运行的结果。所以我们在使用RowNumber函数的时候一定要确保Tablix中的最小粒度要和数据集的粒度保持一致,否则统计出来的行号就会像上图一样是完全错误的。
正确使用RowNumber函数生成行号就可以设置报表为隔行变色的效果: